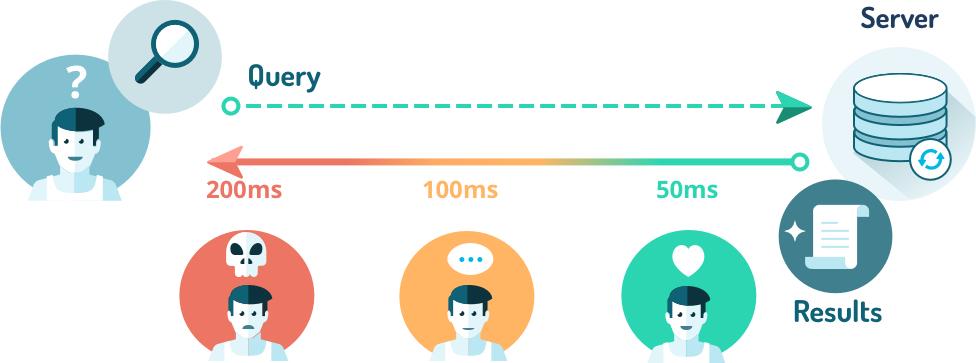
Some says that Symfony2, as every complex framework, is a slow one. Our answer’s that everything depends on you
In that post, we’ll reveal some software architecture details of the Symfony2 based application running more than 1 000 000 000 requests every week.
(..)
Stack architecture
Application
The whole traffic goes to the HAProxy which distributes it to the application servers.
In front of the application instances stays Varnish Reverse Proxy.
We keep Varnish in every application’s server to keep high availability – without having a single point of failure (SPOF). Distributing traffic through single Varnish would make it more risky. Having separate Varnish instances makes cache hits lower but we’re OK with that. We needed availability over a performance but as you could see from the numbers, even the performance isn’t a problem
Application’s server configuration:
- Xeon [email protected], 64GB RAM, SATA
- Apache2 (we even don’t use nginx)
- PHP 5.4.X running as PHP-FPM, with APC
Data storage
We use Redis and MySQL for storing data. The numbers from them’re also quite big:
- Redis:
- 15 000 hits/sec
- 160 000 000 keys
- MySQL:
- over 400 GB of data
- 300 000 000 records
We use Redis both for persistent storage (for the most used resources) and as a cache layer in front of the MySQL. The ratio of the storage data in comparison to the typical cache is high – we store more than 155.000.000 persistent-type keys and only 5.000.000 cache keys. So in fact you can use Redis as a primary data store
Redis is configured with a master-slave setup. That way we achieve HA — during an outage we’re able to quickly switch master node with one of a slave ones. It’s also needed for making some administrative tasks like making upgrades. While upgrading nodes we can elect new master and than upgrade the previous one, at the end switch them again.
We’re still waiting for production-ready Redis Cluster which will give features like automatic-failover (and even manual failover which is great for e.g. upgrading nodes). Unfortunately there isn’t any official release date given.
MySQL is mostly used as a third-tier cache layer (Varnish > Redis > MySQL) for non-expiring resources. All tables are InnoDB and most queries are simple
SELECT ... WHERE 'id'={ID}which return single result. We haven’t noticed any performance problems with such setup yet.In contrast to the Redis setup, MySQL is running in a master-master configuration which besides of High Availability gives us better write performance (that’s not a problem in Redis as you likely won’t be able to exhaust its performance capabilities
Read all about it @ http://labs.octivi.com/handling-1-billion-requests-a-week-with-symfony2/