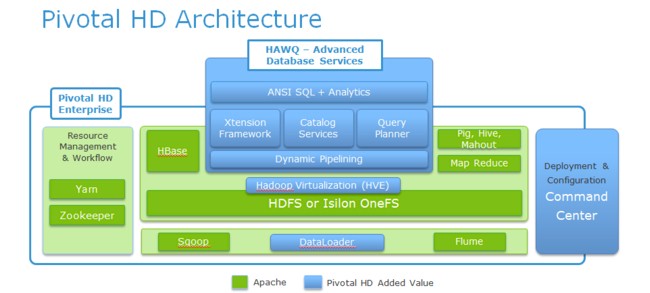
HAWQ is a native, mature and fast SQL Query Engine for Hadoop.
HAWQ enables existing SQL skillsets on Hadoop with benefits.
- Parallel Query Optimizer
- Dynamic Pipelining
- Pivotal Extension Frameworks
- Advanced Analytics Functions
Read the full article
http://www.gopivotal.com/pivotal-products/data/pivotal-hd#4More stolen paragraphs (paragraphs, images and diagrams)!!
The Hadoop big-data muncher has been sitting side-by-side with relational databases used in transaction processing and data warehousing systems, but they speak very different languages. Sure, you can use the Hive SQL-like data warehousing overlay for the Hadoop Distributed File System (HDFS), but queries are not necessarily fast
(…)
Project Hawq, the SQL database layer that rides atop of HDFS rather than trying to replace it with a NoSQL data store, will be part of (…) Pivotal Hadoop Distribution, or Pivotal HD for short.
(…)
there is a Pivotal HD Community Edition, a free distribution used for experimentation, an Enterprise Edition that does not have the SQL-on-HDFS database feature but does have enterprise-grade support for a fee, and an add-on to the Enterprise Edition called Pivotal Advanced Database Services that adds this SQL query capability to data stored in HDFS
(…)
The Hawqextensions to Hadoop’s HDFS turn it into a database, explained Josh Klahr, product manager for the Pivotal HD line at EMC. “Hawq really is a massively parallel processing, or MPP, database running in Hadoop, running on top of HDFS,” he said, “embedded, as one single system, one piece of converged infrastructure that can run and deliver all of the great things that Hadoop and HDFS have to offer as well as the scale and performance and queriability [his word, not ours] that you get from an MPP database.”
(…)
“It really is SQL-compliant, and I don’t use those terms lightly,” Klahr explained further. “It is not SQL-ish, it is not SQL-like. The Hawq allows you to write any SQL query and have it work on top of Hadoop. SQL-99, SQL-92, SQL-2011, SQL-2003, and I am sure there are some other years in there as well.”
(…)
The SQL engine running on top of Hadoop and HDFS is built to scale on top of hundreds to thousands of server nodes and it is derived from the optimizers in the Greenplum database – hence, why we won’t see them opened up.
Read the full article
http://www.theregister.co.uk/2013/02/25/emc_pivotal_hd_hadoop_hawq_database/
The emergence of the Hadoop software framework has enabled the ingest of a wide variety of unstructured data. This makes Hadoop a perfect framework for implementing “analytic correctness”. Big Data applications now have a huge repository for unstructured content that can be queried/analyzed using a parallel approach.
Hadoop, however, has also been disruptive from a toolset perspective: most enterprise customers have made a large investment in SQL skillsets and tools. This expertise cannot simply be re-purposed to an all-Hadoop framework; the majority of legacy corporate value still lies embedded in row-column, structured formats.
Running one analytic model against both structured and unstructured data requires a unified toolset.
(…)
HAWQ has evolved from the original Greenplum SQL engine (optimized for parallel execution over the last 10 years). The real story, however, is the integration with Hadoop under the covers. The integration allows enterprise customers to continue leveraging their SQL tools and skillsets, while blending the integration of structured and unstructured analysis.
Read the full article
http://stevetodd.typepad.com/my_weblog/2013/02/onward-to-analytic-correctness.html